Sometimes, you have to take a bath to make things come together. In my case, I was pondering porting the absolutely fabulous nanoloop to the iPhone platform. But that was only one piece of the puzzle. The other one was a podcast (Bitsundso) where one of the regulars (namely Thorsten Philipp) was explaining the brand new apple flavor of http streaming – Which is based on delivering a video or audio stream in small chunks (8-10 seconds seems to be a good value) and glueing them together using an extended version of m3u-playlists.
But first, a bit of background. Nanoloop is a music synthesizer/sequencer for the Gameboy, more specificly for the Gameboy Classic and the Gameboy advance (those are two different versions). I am a proud owner of one of the Nanoloop 2.3 cartridges, wich are handmade by Hamburgian resident and 8Bit-Superstar Oliver Wittchow. Editing music with the not-exactly-rich user interface of a handheld game console (a screen and 10 buttons: Left, Right, Up, Down, Start, Select, A, B, L and R) is challenging. Managable and, as Youtube or even my very own Soundcloud stream testifies, with usable results, but, nevertheless, far from being intuitive. Oliver did his best to streamline the experience and to make everything as consistent as possible, but still.
Now, my plan was (and still is) to either convince Oliver to port Nanoloop to the iPhone or to do a knock off of it myself. Here’s the problem: While porting the sound engine should not be a huge problem (both devices are using ARM architecture, plus the iPhone should be an order of a magnitude faster), the interface has to be completely different. Because the iPhone has no buttons. Well, strictly speaking it has four buttons and a rocker switch, but none of them are usable in your own software. What it has, though, is a touch screen. Multitouch, even.
So the real challenge of a nanoloop port would be to convert the user interface from a stricly “hold button A and use cursor keys to change the value of the current note” interface to a simple, elegant and intuitive touch interface. Because, you know, as unintuitive the button interface may seem at first, as with every game controller, after a few hours of usage, it all starts to make sense. And in the end, you are pretty fast using the damn thing. Because, there are worlds to rescue. Or songs to write. And you’d have to be extremely careful not to lose this sense of speed when converting the interface to a touch version.
Anyway, since I am a much better HTML+Javascript coder than I am an iPhone developer, I thought, well, let’s prototype the interface in HTML. I could even build a version that’s compatible to the iPhone, so one could check the usability on the target device.
And then I thought: Yeah, well, but why stop there. Why not building a web version of Nanoloop. With a serverside sound generator and with realtime streaming, using this cool new Apple technology.
So, here we go. In the following, I’ll describe parts of the puzzle and how I solved them. Please note that this is far from finished, all that’s there as I speak is a very rough prototype that has enough problems to make a hard man cry. Nevertheless, you can find the code on github .
The Interface
I started off with the interface. This is what the nanoloop interface looks most of the time:
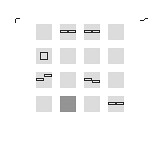
The grey boxes are 16 steps of a simple step sequencer and the black small rectangles are the visualisation of the data you edit (the screen you look at is for editing per step pitch envelopes).
I decided to use the canvas element for the visualisation. I am still not sure if something like SVG (and raphael.gs for example) would not be better, but, hey, this is just a first shot. I also decided to use one canvas element per step. So it’s 16 little canvasses there, neatly aligned and centered on the screen. The rest is just a big fat, query based javascript hack that will need a lot of refactoring, very soon.
Don’t expect much of a good interface conversion, too. I just did the first thing that came to mind, namely popping up a bigger version of the step as soon as you click on one and closing it again after you click into this big step window. A real iphone version would most certainly allow such a click action as well as a “press-down, open big step, adjust values, release, close big step” variant. But, it’s a start.
The Synth
The next thing I tackled was the sound generation. I briefly thought about reusing my cmusic code from Soundbadge but I wasn’t sure if cmusic would be flexible enough for the stuff I had in mind. What I really wanted was using ruby for the sound generation. So I started to look for a way to render sound files from ruby. Remember: The goal was to output small chunks of audio in a format understandable by Quicktime. My thinking was “naw, encoding mp3 in ruby will probably be a dealbreaker, so simply render out wav files and encode them using a command line utility to something usable.”. And something great I found. The Ruby Application Archive spat out sndlib a library for a lot of sound related stuff written in C with bindings for Ruby and quite some other languages. You only get the source, so it’s configure>make time, but that was pretty easy. The first pifall was that the usual “sudo make install” didn’t install the ruby extension into the right place. So I had to manually copy the sndlib.bundle file (Yep, I’m on a mac, under Unix, this probably woulda been sndlib.so) to /usr/lib/ruby/site_ruby/1.8/universal-darwin10.0/ yadda, yadda. Be also prepared for what may very well be the worst documentation for a project, evar.
But the binding is actually quite nice. There’s a cool SoundData utility class which will act as a sample buffer which you can use to write to the sound files (or sound hardware, if you must).
It also contains quite a few utility functions to generate music and currently I’m using both the sawtooth generator to create the base sound for my synthesizer and the envelope generator.
Hacking the synth together was pretty easy. Writing the sound files in wav format, using the correct, fixed chunk size was a bit hairy and I also expect some bugs to lurk around there (more on that later). Bringing it all to work with Quicktime was a pretty bad experience. Not that anything in there is complicated (you most probably want to use ffmpeg for encoding the files although in theory lame should be fine), but the level of feedback you can expect from Quicktime if anything is wrong feels like it’s 1991 all over again. Error -120203 or something like that. Yeah, right, that one. The devil is in the detail, in my case, my playlist had a small syntax error.
The Streaming
Ah, while we’re at it. The playlist. To concat all the small bits of sound into a coherent music stream, you’ll need a playlist. since it is realtime streaming, it’s a playlist with a sliding window of stream urls in it. Let’s say you have generated 3 streaming parts up to now. The playlist would look something like this:
#EXTM3U
#EXT-X-TARGETDURATION:5
#EXT-X-ALLOW-CACHE:yes
#EXT-X-MEDIA-SEQUENCE:0
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_1.ts
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_2.ts
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_3.tsNow, if you have your 1000th part generated, the playlist would look like this (I left out the unimportant header bits)
#EXT-X-MEDIA-SEQUENCE:995
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_995.ts
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_996.ts
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_997.ts
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_998.ts
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_999.ts
#EXTINF:5,
http://halfmac.local/~jan/webloop/app/test_1000.tsSo, but how does the streaming work now? Easy. The client (The only client that can do this right now, is quicktime) loads the playlist, fetches the first few stream bits and starts playing them. As soon as it comes to the end of the playlist, it reloads the playlist which now should, ideally, contain links to new streaming bits. To let the client know where exactly he should look, you provide the #EXT-X-MEDIA-SEQUENCE tag.
Now, to be able to stream the generated sound, sound generation needs to be faster than realtime (because of the additional step of converting the wave to a streamable format). Luckily, this is, at least on my Core II Duo iMac, still the case. I’m most curious how well this will work on, let’s say, a vServer where I could deploy this stuff.
The Duct Tape
So I had the sound generation in place, the last thing to do was to glue the web interface and the sound generation together.
Sinatra to the rescue: Three actions, one to transmit changes from the frontend to the server, one to poll the data so that the web editor is updated if someone else at the other end of the world changes something in his view (yes, this is a distributed sound editor, please don’t get too exited…), one to fetch the playlist (Quicktime is a bit picky on the mime type the playlist has to be delivered in, that’s why I have to deliver the playlist with an action).
The last bit is almost boring: Safari, in it’s current incarnation, supports the html5 audio tag. What’s even better: It supports quicktime realtime streaming using the audio tag. Here’s the code:
<audio src="/playlist.m3u8" autoplay="autoplay" autobuffer="autobuffer" />yip, that’s it. It starts playing (most of the time) as soon as you open the page.
Data storage for the pattern data is currently extremely high tech: A yaml file. A good idea would probably be to change this to an in-mem store (memcached, redis maybe?) and randomly write it to disk to have a backup.
The Drawbacks
Well, streaming always comes with latency. Since this http streaming doesn’t involve any kind of QoS control or other forms of stream control I don’t know shit about, http streaming seems to come with very much latency. I’m pretty sure you could tweak it by setting different chunk sizes and stuff, but here you go. Having a sound editor with over 20 seconds of latency is probably not very practical (although I must say that the nature of nanoloops editor makes it quite possible to work with it).
The other problem is that playback is not entirely bug free (as stated above). Sometimes it seems as if the chunks align perfectly, sometimes they don’t. I am not done debugging this, but maybe there’s an underlying problem I didn’t see in the first place.
The Future
First of all, the user interface code needs some mean refactoring. Then I could add different pattern views to allow editing more than one parameter. I have at least two parameters (Envelope and Sound) that are already present in the synth (and also in the pattern yaml file), so this should be fun and easy.
Next up: I was thinking a bit more about the synthesizer infrastructure and maybe I should try to aim for a bit more of a flexible infrastructure and a variable backend. The current solution works, but poorly and is extremely low tech. So, why not making the synth entirely realtime and stream based (makes it more fun to debug if you could listen directly to it) and then using the recipe of Thorsten Philipp to take a real stream and slash it into pieces. That way, I could also stream it as an icecast stream if I wanted to.
Ah, the possibilites. Good to know that there’s a music hackday coming up :)
The Video
Last but not least, I give you this:
